
En colaboración con la Cátedra RTVE-UGR, Monoceros Labs ha participado en un proyecto multidisciplinar centrado en el desarrollo de herramientas para la detección de audios falsos.
Nuestra contribución se ha enfocado en la creación de voces sintéticas clonadas de alta calidad para el entrenamiento y evaluación de modelos de detección de deepfakes de audio, también conocidos como audios falsos que suplantan la identidad de una persona.
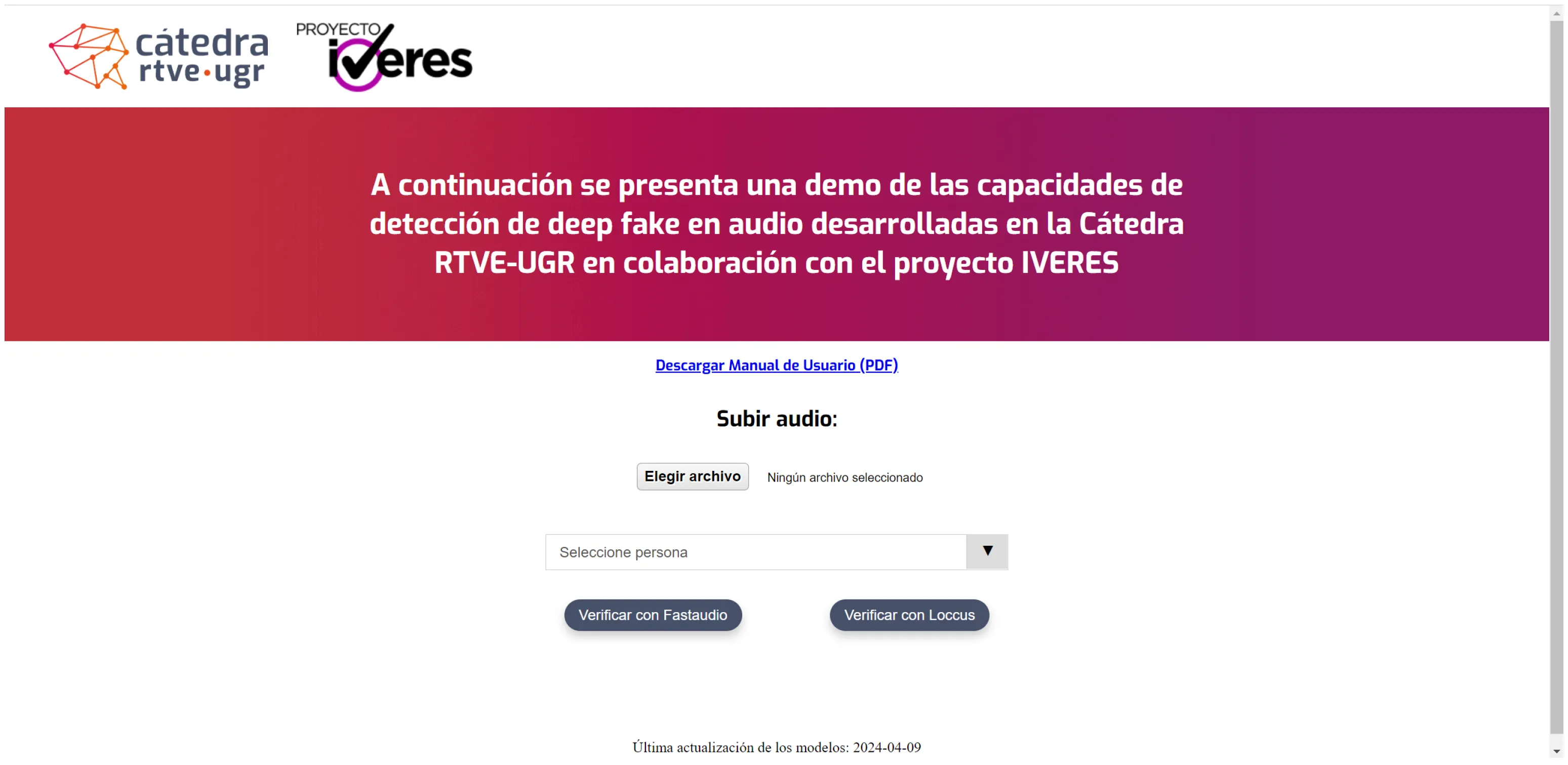
El proyecto ha desarrollado una herramienta para verificar audios que está a disposición de VerificaRTVE y de otras agencias a través del Proyecto IVERES.
La proliferación de audios falsos o deepfakes representa una amenaza creciente para la integridad de la información y de nuestra sociedad. El proyecto busca:
Más información en el artículo científico publicado en 2024:
Nuestro trabajo se centró en la creación de voces sintéticas clonadas de personas relevantes, pertenecientes al Rey Felipe VI; el presidente del Gobierno, Pedro Sánchez, o la vicepresidenta Yolanda Díaz. Se utilizaron para ello dos técnicas diferentes:
Síntesis de voz (TTS):
Conversión de voz (STS):
El proceso de desarrollo de los clones de voz siguió un enfoque riguroso:
Selección de datos de voz:
Procesamiento de audio:
Entrenamiento controlado, privado y seguro:
Una vez generados los modelos de voz, se generaron audios falsos, y junto a los reales usados para el entrenamiento, se creó un conjunto de datos para entrenar un clasificador que detectara audios falsos de las personas objetivo.
Como parte del proyecto, se desarrolló un clasificador de detección de deepfakes específico para las voces clonadas. Se entrenó con miles de audios por cada voz objetivo, tanto reales como falsos, es decir, generados con las voces clonadas.
El clasificador utiliza una arquitectura basada en FastAudio, que es capaz de adaptarse dinámicamente a las características de las amenazas de spoofing. A diferencia de los sistemas tradicionales, nuestro clasificador utiliza capas de filtros que se ajustan durante el entrenamiento, permitiendo una detección más precisa de las manipulaciones de audio.
El proyecto destaca por varios elementos únicos:
Nuestra contribución ha sido fundamental para:
Esta colaboración, enmarcada como ya hemos mencionado en el proyecto IVERES, ha recibido el siguiente reconocimiento: -“Proyecto público” en los II premios nacionales otorgados por el Consejo General de Colegios de Ingeniería Informática.
Este proyecto representa un ejemplo de cómo la tecnología de síntesis de voz puede aplicarse de manera responsable para combatir la desinformación. La colaboración entre diferentes actores nos ha permitido crear herramientas más efectivas para la verificación de audios, contribuyendo a la integridad de la información en el entorno digital.